Развитието на кешовете и кеширането е едно от най-значимите събития в историята на изчислителната техника. Почти всеки съвременен процесор, започвайки от тези с ултраниска консумация като ARM Cortex-A5 до най-високия клас Intel Core i7, използва кешове. Дори и по-високият клас микроконтролери често имат малък кеш или го предлагат като опция – ползите за производителността са твърде значителни, за да се игнорират, дори в конструкциите с ултраниска консумация на енергия.
Кеширането е измислено, за да реши един сериозен проблем. В първите десетилетия на компютрите основната памет бе изключително бавна и невероятно скъпа, но и процесорите също не бяха особено бързи. Започвайки от 1980 г., разликата между тях започна да се увеличава много бързо. Скоростите на микропроцесорите тръгнаха стръмно нагоре, но времената за достъп до паметта се увеличаваха далеч по-малко драматично. Тъй като тази пропаст взе да нараства, ставаше все по-ясно, че е необходим нов тип бърза памет, за да бъде преодоляна разликата.

Въпреки че графиката е само до 2000 г., растящото несъответствие, започващо от 1980 г., доведе до създаването на първите процесорни кешове.
Как работи кеширането
CPU кешовете са малки набори от памет, съхраняващи информация, от която има най-голяма вероятност процесорът да се нуждае в следващата стъпка. Зарежданата информация в кеша зависи от сложни алгоритми и някои предположения за програмния код. Целта на кеш системата е да гарантира, че следващият бит от данни, който ще бъде необходим на процесора, е вече зареден в кеша, преди времето, когато той ще отиде да го търси (нарича се коефициент на попадения).
Липсата на кеш L1, от друга страна, означава, че процесорът трябва да се втурне да търси данните на друго място. За да не стига чак до основната памет, което много ще го забави, в играта влиза кеша L2 – той е по-бавен, но също и много по-голям. Някои процесори използват интегриран кеш дизайн (което означава, че данните, съхранявани в кеш L1, също се дублират в кеш L2), докато други не използват такова интегриране(което означава, че двата кеша никога не си обменят данни). Ако данните не могат да бъдат намерени в кеш L2, процесорът продължава надолу по веригата към L3 (обикновено също върху интегралната схема), след това към L4 (ако има такъв) и към основната памет (DRAM).

Тази таблица показва отношенията на кеш L1 с постоянен коефициент на попадения с по-голям L2 кеш. Имайте предвид, че общият процент попадения се увеличава рязко с размера на увеличение на L2. По-големият, по-бавен и по-евтин L2 може да осигури всички предимства на голям L1, но без да се заплаща с размера на интегралната схема и консумацията на енергия. Повечето съвременни L1 кеш имат коефициент на попадения далеч над теоретичния от 50%, показан тук – Intel и AMD постигат нормално коефициент на попадение от 95% или по-висок.
Следващата важна тема е асоциативността на набора от кешове. Всеки централен процесор съдържа определен тип RAM, наречена таг-RAM. RAM тагът е запис на всички места с памет, които могат да се асоциират с блок на кеша. Ако паметта е напълно асоциативна, това означава, че всеки блок RAM данни могат да се съхраняват във всеки блок на кеша. Предимството на тази система е, че процентът на попадения е много висок, но времето за търсене е изключително дълго – процесорът трябва да прегледа целия си кеш, за да разбере дали данните се намират там, преди да търси в основната памет.
В противоположния край на спектъра имаме директно асоциирани кешове. Те са кеш, при който всеки кеш блок може да се асоциира с един и само с един блок от основната памет. Този тип кеш може да бъде претърсван изключително бързо, но тъй като се асоциира 1:1 с паметта, той има нисък процент на попадения. Между тези две крайности са n-лентовите асоциирани кешове. Един 2-лентов асоциативен кеш означава, че всеки основен блок памет може се асоциира към един от два кеш блока. Осем-лентов асоциативен кеш означава, че всеки блок на главната памет може да бъде в една от осемте кеш блокове.
Следващите две графики показват как коефициентът на попадения се подобрява с комплекта асоциативен кеш. Имайте предвид, че процентът на попадения е много специфичен – различни приложения ще имат много различни проценти на попадения.

Защо CPU кешoвете продължават да стават все по-големи
Защо все пак се добавят непрекъснато големи кешове? Тъй като всеки допълнителен набор памет изтласка още по-назад необходимостта от достъп до основната памет и може да подобри производителността в определени случаи.

Тази графика на тест на Haswell от AnandTech е полезна, защото тя всъщност илюстрира въздействието върху производителността от добавянето на огромен (128 MB) L4 кеш, както и от конвенционалните L1, L2 и L3 структури. Всяка стъпка от стълбичката представлява ново ниво на кеша. Червената линия е чип с L4 – имайте предвид, че за големи размери на файла, той все още е почти два пъти по-бърз от другите два Intel чипа.
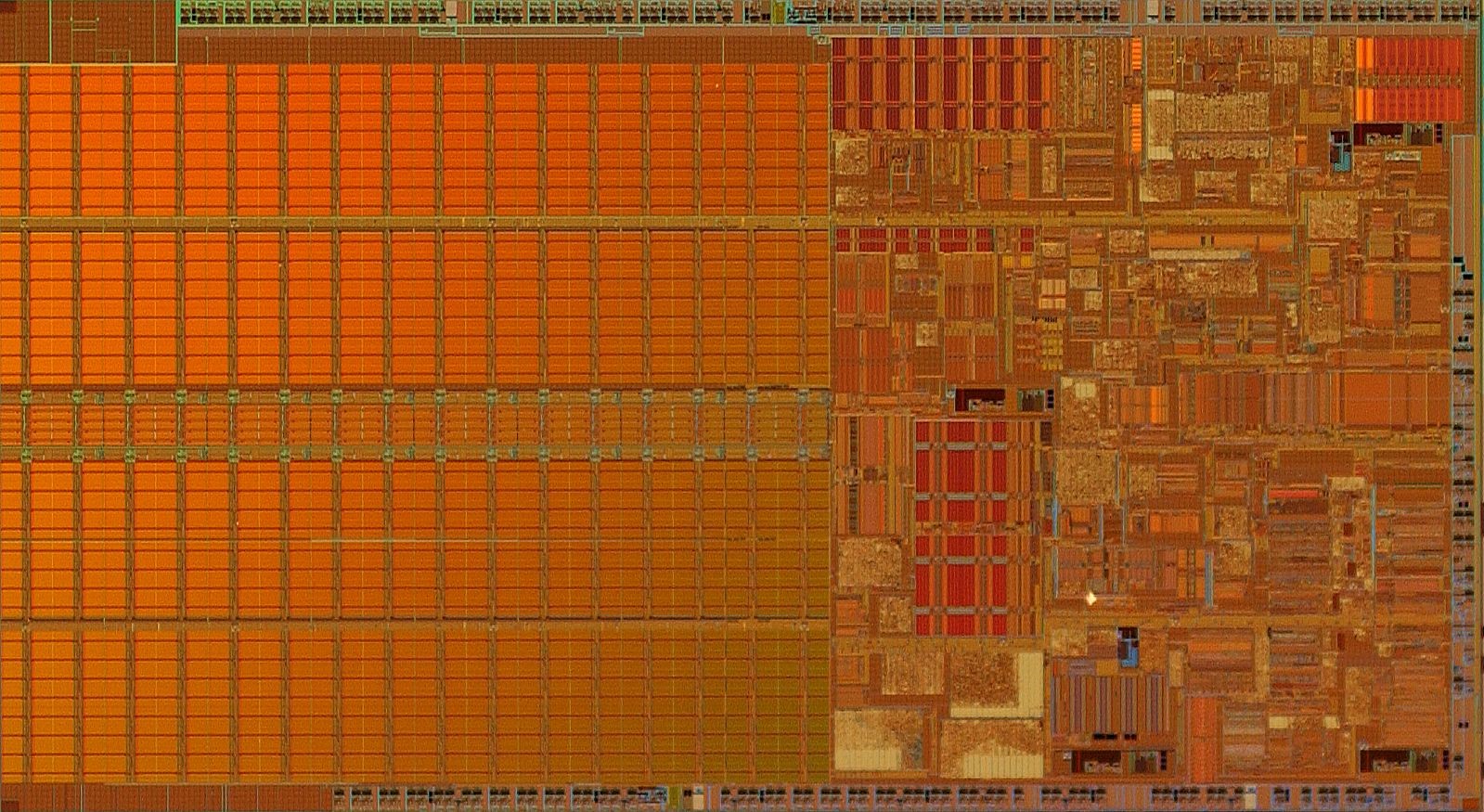
Следователно може да изглежда логично, да се предвидят огромни количества ресурси върху интегралната схема за кеш, но се оказва, че има намаляващ предел на възвръщаемостта за това. По-големите кешове са както по-бавни, така и по-скъпи. При шест транзистора на бит на SRAM (6T), кешът също е скъп (от гледна точка на размерa на интегралната схема). От един определен момент нататък е по-разумно да се правят разходи за мощност на чипа и броя на транзисторите чрез повече изпълнителни блокове, за по-добри прогнози на разклоненията или за допълнителни ядра. На илюстрацията в началото на статията можете да видите изображение на чип Pentium M (Centrino/Dothan), като цялата лява половина на матрицата е изпълнена с масивна L2 кеш.
Как конструкцията на кеша въздейства на производителността?
Влиянието върху производителността от прибавянето на процесорен кеш е пряко свързано с неговата ефективност или процента на попадения. Повтарящите се пропуски на кеша могат да имат катастрофален ефект върху производителността на процесора. Следващият пример е много опростена, но може да послужи за илюстрация на това твърдение.
Представете си, че един централен процесор трябва да заредите данни от кеш L1 100 пъти подред. Кешът L1 има 1 ns латентност на достъп и коефициент на попадения 100%. Следователно на нашия процесор му отнема 100 наносекунди за извършване на тази операция.

Снимка на Haswell-E интегралната схема. Повтарящите се структури в средата на чипа са 20 MB споделен L3 кеш.
Сега да предположим, че кешът има коефициент на попадения 99%, но данните, от които процесорът всъщност се нуждае за своя 100% достъп, са в L2, който е с 10-цикъла (10 ns) латентност на достъпа. Това означава, че на процесора му трябват 99 наносекунди за извършване на първите 99 прочитания и 10 наносекунди за извършване на 100-ното. Така понижаването на коефициента на попаденията с 1% забавя процесора с 10%.
В реалния свят кешът L1 обикновено има коефициента на попаденията между 95% и 97%, но разликата във въздействието върху производителността на тези две стойности в нашия прост пример не е 2%, а 14%. Имайте предвид, че ние приемаме, че пропуснатите данни винаги седят в кеш L2. Ако данните вече са били изпразнени от кеша в основната памет с латентност на достъп от 80-120 ns, разликата в производителността между коефициентите на попадения от 95% и 97% би могла почти да удвои общото време, необходимо за изпълнение на кода.
Когато семейството процесори Bulldozer на AMD се сравнява с процесори на Intel, темата за дизайна на кеша и въздействието върху производителността се появява с пълна сила. Не е ясно колко от проблемите с производителността на Bulldozer могат да бъдат приписани на сравнително бавната му кеш подсистема – в допълнение към относително високата латентност, семейството Bulldozer също страда от високо количество неразбирателства в кеша.
Кешът е в неразбирателство, когато две различни изпълнявани нишки код, пишат и презаписват данни в едно и също пространство памет. Това нарушава производителността и на двете нишки – всяко ядро е принудено да губи време в писане на собствените си предпочитани данни в L1, само за да може другото ядро незабавно да презапише тази информация.
Кеширането продължава напред
Кеш структурите и дизайните продължават да се прецизират, като изследователите търсят начини да изстискат по-висока производителност от по-малките кеш. Има едно старо правило, че добавяме грубо едно ниво кеш на всеки 10 години, и изглежда, че то е вярно и до днес – Haswell и Broadwell чиповете на Intel предлагат някои вариации с огромен L4, като по този начин продължават тенденцията.

Отворен въпрос на този етап е дали AMD някога ще тръгне по този път. Компанията набляга на HSA (Heterogeneous System Architecture) са спецификации, които позволяват интеграция на централен и графичен процесор на една шина със споделени памет и задачи) и споделени изпълнителни ресурси и изглежда, че ще тръгне по различен път.
Независимо от всичко, кеш дизайнът, консумацията на енергия и производителността ще бъдат от решаващо значение за работата на бъдещите процесори, като осъществяването на съществени подобрения на текущите конструкции може да засили статута на онази компания, която го направи.


